Simple note about using JPA relation mappings
14 February 2020
There is a lot of typical examples how to build JPA @OneToMany and @ManyToOne relationships in your Jakarta EE application. And usually it looks like:
@Entity
@Table(name = "author")
public class Author {
@OneToMany
private List<Book> book;
...
}
@Entity
@Table(name = "book")
public class Book {
@ManyToOne
private Author author;
...
}
This code looks pretty clear, but on my opinion you should NOT USE this style in your real world application. From years of JPA using experience i definitely can say that sooner or later your project will stuck with known performance issues and holy war questions about: N+1, LazyInitializationException, Unidirectional @OneToMany , CascadeTypes ,LAZY vs EAGER, JOIN FETCH, Entity Graph, Fetching lot of unneeded data, Extra queries (for example: select Author by id before persist Book) etcetera. Even if you are have answers for each potential issue above, usually proposed solution will add unreasonable complexity to the project.
To avoid potential issues i recommend to follow next rules:
- Avoid using of
@OneToManyat all - Use
@ManyToOneto build constrains but work with ID instead of Entity
Unfortunately, simple snippet below does not work as expected in case persist
@ManyToOne(targetEntity = Author.class)
private long authorId;
But,we can use next one instead of
@JoinColumn(name = "authorId", insertable = false, updatable = false)
@ManyToOne(targetEntity = Author.class)
private Author author;
private long authorId;
public long getAuthorId() {
return authorId;
}
public void setAuthorId(long authorId) {
this.authorId = authorId;
}
Hope, this two simple rules helps you enjoy all power of JPA with KISS and decreasing count of complexity.
ISPN000299: Unable to acquire lock after 15 seconds for key
05 February 2020
Distributed cache is a wide used technology that provides useful possibilities to share state whenever it necessary. Wildfly supports distributed cache through infinispan subsystem and actually it works well, but in case height load and concurrent data access you may run into a some issues like:
- ISPN000299: Unable to acquire lock after 15 seconds for key
- ISPN000924: beforeCompletion() failed for SynchronizationAdapter
- ISPN000160: Could not complete injected transaction.
- ISPN000136: Error executing command PrepareCommand on Cache
- ISPN000476: Timed out waiting for responses for request
- ISPN000482: Cannot create remote transaction GlobalTx
and others.
In my case i had two node cluster with next infinispan configuration:
/profile=full-ha/subsystem=infinispan/cache-container=myCache/distributed-cache=userdata:add()
/profile=full-ha/subsystem=infinispan/cache-container=myCache/distributed-cache=userdata/component=transaction:add(mode=BATCH)
distributed cache above means that number of copies are maintained, however this is typically less than the number of nodes in the cluster. From other point of view, to provide redundancy and fault tolerance you should configure enough amount of owners and obviously 2 is the necessary minimum here. So, in case usage small cluster and keep in mind the BUG, - i recommend use replicated-cache (all nodes in a cluster hold all keys)
Please, compare Which cache mode should I use? with your needs.
Solution:
/profile=full-ha/subsystem=infinispan/cache-container=myCache/distributed-cache=userdata:remove()
/profile=full-ha/subsystem=infinispan/cache-container=myCache/replicated-cache=userdata:add()
/profile=full-ha/subsystem=infinispan/cache-container=myCache/replicated-cache=userdata/component=transaction:add(mode=NON_DURABLE_XA, locking=OPTIMISTIC)
Note!, NON_DURABLE_XA doesn't keep any transaction recovery information and if you still getting Unable to acquire lock errors on application critical data - you can try to resolve it by some retry policy and fail-fast transaction:
/profile=full-ha/subsystem=infinispan/cache-container=myCache/distributed-cache=userdata/component=locking:write-attribute(name=acquire-timeout, value=0)
Logging for JPA SQL queries with Wildfly
10 January 2020
Logging for real SQL queries is very important in case using any ORM solution, - as you never can be sure which and how many requests will send JPA provider to do find, merge, query or some other operation.
Wildfly uses Hibernate as JPA provider and provides few standard ways to enable SQL logging:
1. Add hibernate.show_sql property to your persistence.xml :
<properties>
...
<property name="hibernate.show_sql" value="true" />
...
</properties>
INFO [stdout] (default task-1) Hibernate: insert into blogentity (id, body, title) values (null, ?, ?)
INFO [stdout] (default task-1) Hibernate: select blogentity0_.id as id1_0_, blogentity0_.body as body2_0_, blogentity0_.title as title3_0_ from blogentity blogentity0_ where blogentity0_.title=?
2. Enable ALL log level for org.hibernate category like:
/subsystem=logging/periodic-rotating-file-handler=sql_handler:add(level=ALL, file={"path"=>"sql.log"}, append=true, autoflush=true, suffix=.yyyy-MM-dd,formatter="%d{yyyy-MM-dd HH:mm:ss,SSS} %-5p [%c] (%t) %s%e%n")
/subsystem=logging/logger=org.hibernate.SQL:add(use-parent-handlers=false,handlers=["sql_handler"])
/subsystem=logging/logger=org.hibernate.type.descriptor.sql.BasicBinder:add(use-parent-handlers=false,handlers=["sql_handler"])
DEBUG [o.h.SQL] insert into blogentity (id, body, title) values (null, ?, ?)
TRACE [o.h.t.d.s.BasicBinder] binding parameter [1] as [VARCHAR] - [this is body]
TRACE [o.h.t.d.s.BasicBinder] binding parameter [2] as [VARCHAR] - [title]
DEBUG [o.h.SQL] select blogentity0_.id as id1_0_, blogentity0_.body as body2_0_, blogentity0_.title as title3_0_ from blogentity blogentity0_ where blogentity0_.title=?
TRACE [o.h.t.d.s.BasicBinder] binding parameter [1] as [VARCHAR] - [title]
3. Enable spying of SQL statements:
/subsystem=datasources/data-source=ExampleDS/:write-attribute(name=spy,value=true)
/subsystem=logging/logger=jboss.jdbc.spy/:add(level=DEBUG)
DEBUG [j.j.spy] java:jboss/datasources/ExampleDS [DataSource] getConnection()
DEBUG [j.j.spy] java:jboss/datasources/ExampleDS [Connection] prepareStatement(insert into blogentity (id, body, title) values (null, ?, ?), 1)
DEBUG [j.j.spy] java:jboss/datasources/ExampleDS [PreparedStatement] setString(1, this is body)
DEBUG [j.j.spy] java:jboss/datasources/ExampleDS [PreparedStatement] setString(2, title)
DEBUG [j.j.spy] java:jboss/datasources/ExampleDS [PreparedStatement] executeUpdate()
DEBUG [j.j.spy] java:jboss/datasources/ExampleDS [PreparedStatement] getGeneratedKeys()
DEBUG [j.j.spy] java:jboss/datasources/ExampleDS [ResultSet] next()
DEBUG [j.j.spy] java:jboss/datasources/ExampleDS [ResultSet] getMetaData()
DEBUG [j.j.spy] java:jboss/datasources/ExampleDS [ResultSet] getLong(1)
DEBUG [j.j.spy] java:jboss/datasources/ExampleDS [ResultSet] close()
...
DEBUG [j.j.spy] java:jboss/datasources/ExampleDS [DataSource] getConnection()
DEBUG [j.j.spy] java:jboss/datasources/ExampleDS [Connection] prepareStatement(select blogentity0_.id as id1_0_, blogentity0_.body as body2_0_, blogentity0_.title as title3_0_ from blogentity blogentity0_ where blogentity0_.title=?)
DEBUG [j.j.spy] java:jboss/datasources/ExampleDS [PreparedStatement] setString(1, title)
DEBUG [j.j.spy] java:jboss/datasources/ExampleDS [PreparedStatement] executeQuery()
DEBUG [j.j.spy] java:jboss/datasources/ExampleDS [ResultSet] next()
DEBUG [j.j.spy] java:jboss/datasources/ExampleDS [ResultSet] getLong(id1_0_)
DEBUG [j.j.spy] java:jboss/datasources/ExampleDS [ResultSet] wasNull()
DEBUG [j.j.spy] java:jboss/datasources/ExampleDS [ResultSet] getString(body2_0_)
DEBUG [j.j.spy] java:jboss/datasources/ExampleDS [ResultSet] wasNull()
DEBUG [j.j.spy] java:jboss/datasources/ExampleDS [ResultSet] getString(title3_0_)
DEBUG [j.j.spy] java:jboss/datasources/ExampleDS [ResultSet] wasNull()
DEBUG [j.j.spy] java:jboss/datasources/ExampleDS [ResultSet] next()
DEBUG [j.j.spy] java:jboss/datasources/ExampleDS [ResultSet] close()
So, from above we can see that variants 2 and 3 is most useful as allows to log queries with parameters. From other point of view - SQL logging can generate lot of unneeded debug information on production. To avoid garbage data in your log files, feel free to use Filter Expressions for Logging
Why Jakarta EE beats other java solutions from security point of view
27 December 2019
No one care about security until security incident. In case enterprise development last one can costs too much, so any preventive steps can help. Significant part part of the OWASP Application Security Verification Standard (ASVS) reads:
10.2.1 Verify that the application source code and third party libraries do not contain unauthorized phone home or data collection capabilities. Where such functionality exists, obtain the user's permission for it to operate before collecting any data.
10.2.3 Verify that the application source code and third party libraries do not contain back doors, such as hard-coded or additional undocumented accounts or keys, code obfuscation, undocumented binary blobs, rootkits, or anti-debugging, insecure debugging features, or otherwise out of date, insecure, or hidden functionality that could be used maliciously if discovered.
10.2.4 Verify that the application source code and third party libraries does not contain time bombs by searching for date and time related functions.
10.2.5 Verify that the application source code and third party libraries does not contain malicious code, such as salami attacks, logic bypasses, or logic bombs.
10.2.6 Verify that the application source code and third party libraries do not contain Easter eggs or any other potentially unwanted functionality.
10.3.2 Verify that the application employs integrity protections, such as code signing or sub-resource integrity. The application must not load or execute code from untrusted sources, such as loading includes, modules, plugins, code, or libraries from untrusted sources or the Internet.
14.2.4 Verify that third party components come from pre-defined, trusted and continually maintained repositories.
In other words that meaning you should: "Verify all code including third-party binaries, libraries, frameworks are reviewed for hardcoded credentials (backdoors)."
In case development according to Jakarta EE specification you shouldn't be able to use poor controlled third party libraries, as all you need already came with Application Server. In turn, last one is responsible for in time security updates, ussage of verified libraries and many more...
How to setup Darcula LAF on Netbeans 11
26 December 2019
It is pity, but Apache Netbeans IDE still comes without support default dark mode. Enabling Netbeans 8.2 Plugin portal does not have any effect, so to use plugins from previous versions we need to add New Provider (Tools->Plugins) with next URL:
http://plugins.netbeans.org/nbpluginportal/updates/8.2/catalog.xml.gz
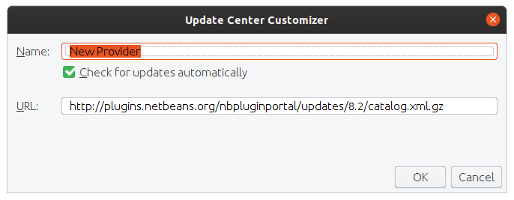
After that you should be able setup Darcula LAF in standard way